
Introducing FinBERT: Tailoring BERT for Financial Sentiment Analysis
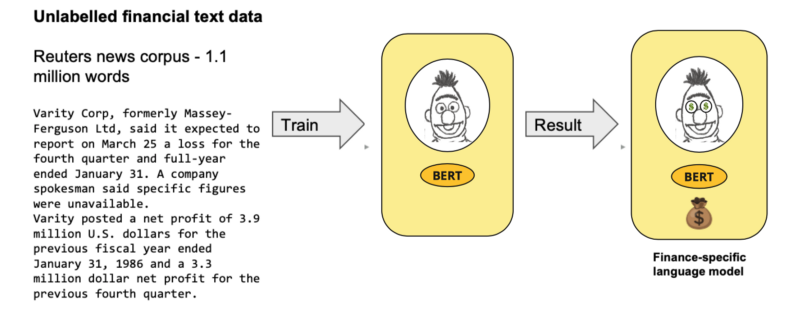
BERT proved to be an optimal fit for our financial sentiment analysis undertaking. Even with a limited dataset, the prospect of harnessing cutting-edge NLP models became attainable. Nevertheless, a vital consideration emerged – our domain, finance, deviated substantially from the general-purpose corpus upon which BERT was pre-trained. Thus, Araci and Genc aspired to introduce an additional phase before sentiment analysis. While pre-trained BERT exhibited a general linguistic proficiency, they aimed to refine its language skills to align with the lexicon of traders. This aspiration led them to augment BERT’s capabilities through further training, specifically targeting financial language nuances.
Araci and Genc’s strategy involved extending BERT’s training using the Reuters TRC2 corpus, which is meticulously designed for financial contexts. The intent was to enhance domain adaptation by exposing the model to the intricate vocabulary and terminology of the financial realm, thereby laying a robust foundation before fine-tuning for the ultimate task – financial sentiment analysis. They performed this additional pre-training of BERT with the invaluable aid of Hugging Face’s remarkable transformers library (then known as pytorch-pretrained-bert), leveraging their provided scripts and resources.
Refining the Pre-Trained and Domain-Adapted Model
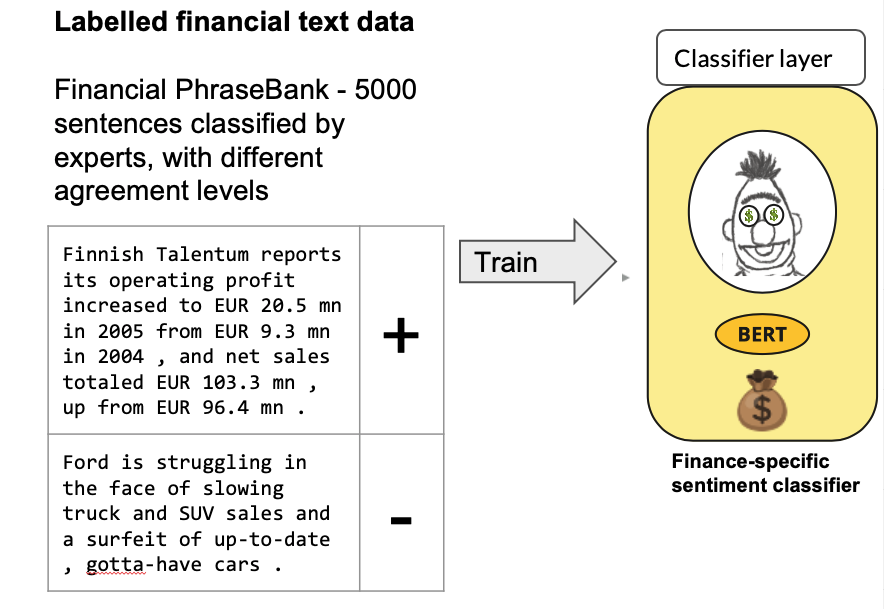
Following acquiring the pre-trained and domain-adapted language model, the subsequent stride involved fine-tuning it using annotated data earmarked for financial sentiment classification. The researchers opted for the Financial Phrasebank dataset for this purpose. This dataset is distinguished by its meticulous annotation despite its modest size. A careful selection process yielded 4500 sentences from diverse news articles, all replete with financial terminology. The process of labelling was undertaken collaboratively by 16 experts and master’s students hailing from finance backgrounds. Notably, the annotations extended beyond mere labels; they also encompassed an evaluation of the inter-annotator agreement level for each sentence. This measure quantified the experts’ consensus in categorizing each sentence as positive, neutral, or negative sentiment.
The Fine-Tuning Process of a Transformer-Based Language Model for Classification
Fine-tuning a language model based on transformers for classification is a relatively straightforward procedure. The initial step entails appending a classification layer after BERT’s specialized token [CLS]. This token is typically utilized in sequential tasks such as sentence classification or textual entailment. Subsequently, the complete model undergoes the fine-tuning process, exposing it to classification-related loss functions. This approach facilitates the adaptation of the general language model to the specific nuances of the classification task at hand.
Source: https://medium.com/prosus-ai-tech-blog/finbert-financial-sentiment-analysis-with-bert-b277a3607101